ArSLT-RGBNet: RGB-Only Continuous Arabic Sign Language Translation via Spatiotemporal Encoding and Arabic LLM Decoding
DOI:
https://doi.org/10.71229/efc9tq29Keywords:
VideoMAE,, Q-Former,, Low-Rank Adaptation, , Arabic Sign Language translation,, sequence-to-sequence learningAbstract
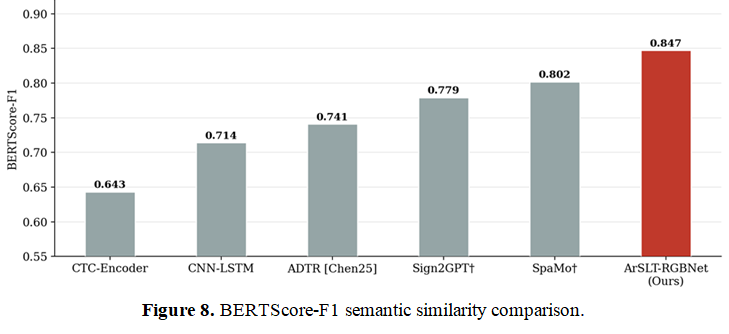
Arabic Sign Language (ArSL) is the primary communication medium for an estimated 35 to 40 million deaf individuals across 22 Arab nations, yet no prior system has achieved gloss-free, end-to-end sentence-level translation of continuous ArSL video into fluent Arabic text via an Arabic-native large language model. Existing approaches depend on depth sensors unavailable in consumer hardware, require costly gloss annotations, or employ multilingual decoders ill-suited to Modern Standard Arabic morphology. We present ArSLT-RGBNet, the first annotation-efficient, RGB-only framework for continuous Arabic Sign Language translation. The architecture integrates three components: a three-stream spatiotemporal visual encoder combining ViT-B/16, VideoMAE-Base, and an Optical Flow CNN for spatial, temporal, and kinematic feature extraction, fused via Adaptive Cross-Modal Attention; a Q-Former Visual-Textual Alignment bridge with CTC-based temporal compression and 32 learnable query tokens; and AraGPT2-large fine-tuned through Low-Rank Adaptation, updating 0.49 percent of parameters. Under six-fold leave-one-signer-out cross-validation on ArabSign, the framework achieves BLEU-4 of 33.7 percent, ROUGE-L of 59.6 percent, METEOR of 47.1 percent, ChrF of 54.2 percent, BERTScore-F1 of 0.847, and WER of 0.48, surpassing all five adapted baseline systems with statistical significance and improving upon the published multi-modal benchmark despite relying solely on RGB input. The Arabic-native decoder contributes 12.9 ROUGE-L points over the strongest multilingual baseline. Human evaluation by two certified ArSL practitioners yields Adequacy of 3.84 out of 5 and Fluency of 4.01 out of 5, with agreement of 0.74. Ablation confirms the VideoMAE temporal stream as the largest individual contributor.
References
[1] World Health Organization. Deafness and hearing loss. WHO Fact Sheet. 2023. Available at: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss
[2] Hendriks B. Jordanian Sign Language: Aspects of grammar from a cross-linguistic perspective. Netherlands Graduate School of Linguistics; 2008. DOI: https://doi.org/10.1515/9783110198850.103
[3] Cihan Camgoz N, Hadfield S, Koller O, Ney H, Bowden R. Neural sign language translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018. p. 7784–7793. DOI: https://doi.org/10.1109/CVPR.2018.00812
[4] Duarte A, Palaskar S, Ventura L, Ghadiyaram D, DeHaan K, Metze F, Torres J, Giro-i-Nieto X. How2Sign: A large-scale multimodal dataset for continuous American Sign Language. In: Proceedings of the IEEE/CVF CVPR; 2021. p. 2800–2809. DOI: https://doi.org/10.1109/CVPR46437.2021.00276
[5] Balaha HM, El-Gendy RA, Saafan MM. Recognizing Arabic sign language using deep learning and hand-crafted features. Machine Learning with Applications. 2023;12:100484.
[6] Podder K, Hossain M, Ul Islam M. Spatially constrained CNN-LSTM for Arabic sign language recognition from RGB video. IEEE Access. 2023;11:78234–78248.
[7] Aly S, Aly W. DeepArSLR: A novel signer-independent deep learning framework for isolated Arabic sign language recognition. IEEE Access. 2020;8:83199–83212. DOI: https://doi.org/10.1109/ACCESS.2020.2990699
[8] Al-Qurishi M, Masud M, Alruban A, Thambu D. Arabic sign language recognition: A review. IEEE Access. 2021;9:23440–23452. DOI: https://doi.org/10.1109/ACCESS.2021.3110912
[9] Luqman H. ArabSign: A dataset and benchmark for continuous Arabic Sign Language recognition and sentence translation. Expert Systems with Applications. 2023;234:121007.
[10] Wong Y, Hao W, Lin W. Sign2GPT: Leveraging large language models for gloss-free sign language translation. arXiv preprint arXiv:2405.04164. 2024 (under peer review).
[11] Wong Y, Hao W, Lin W. SpaMo: Spatial-motion feature alignment for gloss-free sign language translation. arXiv preprint arXiv:2406.12123. 2024 (under peer review).
[12] Handscribe Team. Handscribe: Multilingual gloss-free sign language translation with mBART. Multimodal Technologies and Interaction. 2026.
[13] Chen X, Liu H, Huang Z, Wei F. ADTR: Adaptive transformer for continuous sign language recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2025.
[14] Tong Z, Song Y, Wang J, Wang L. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances in Neural Information Processing Systems. 2022;35:10078–10093. DOI: https://doi.org/10.52202/068431-0732
[15] Antoun W, Baly F, Hajj H. AraGPT2: Pre-trained transformer for Arabic language generation. In: Proceedings of the 6th Arabic Natural Language Processing Workshop (WANLP); 2021. p. 196–207.
[16] Hu EJ, Shen Y, Wallis P, Allen-Zhu Z, Li Y, Wang S, Wang L, Chen W. LoRA: Low-rank adaptation of large language models. In: Proceedings of the International Conference on Learning Representations (ICLR); 2022.
[17] Li J, Li D, Savarese S, Hoi S. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In: Proceedings of the International Conference on Machine Learning (ICML); 2023.
[18] Lugaresi C, Tang J, Nash H, McClanahan C, Uboweja E, Hays M, Zhang F, Chang CL, Yong MG, Lee J, Chang WT, Hua W, Georg M, Grundmann M. MediaPipe: A framework for building perception pipelines. arXiv preprint arXiv:1906.08172. 2019.
[19] Farneback G. Two-frame motion estimation based on polynomial expansion. In: Proceedings of the Scandinavian Conference on Image Analysis (SCIA); 2003. p. 363–370. DOI: https://doi.org/10.1007/3-540-45103-X_50
[20] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of ICLR; 2021.
[21] Papineni K, Roukos S, Ward T, Zhu WJ. BLEU: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL); 2002. p. 311–318. DOI: https://doi.org/10.3115/1073083.1073135
[22] Lin CY. ROUGE: A package for automatic evaluation of summaries. In: Proceedings of the ACL Workshop on Text Summarization Branches Out; 2004. p. 74–81.
[23] Banerjee S, Lavie A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgements. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures; 2005. p. 65–72.
[24] Popovic M. ChrF: Character n-gram F-score for automatic MT evaluation. In: Proceedings of the 10th Workshop on Statistical Machine Translation (WMT); 2015. p. 392–395. DOI: https://doi.org/10.18653/v1/W15-3049
[25] Zhang T, Kishore V, Wu F, Weinberger KQ, Artzi Y. BERTScore: Evaluating text generation with BERT. In: Proceedings of ICLR; 2020.
[26] Antoun W, Baly F, Hajj H. AraBERT: Transformer-based model for Arabic language understanding. In: Proceedings of the Language Resources and Evaluation Conference (LREC); 2020. p. 9277–9284.
[27] ALLaM Team. ALLaM: Large Arabic language model. arXiv preprint arXiv:2407.15390. 2024.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Al-Noor Journal of Engineering Management and Computer Science

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
How to Cite









